Azure data factory is an online data integration service which can create, schedule and manage your data integrations at scale.
Recently I was working with ADF and was using it for transforming the data from various sources using SSIS and hence ADF’s SSIS integration services became the core necessity to run my data factory pipelines.
When we speak of any cloud-based solution – the design part of it needs to be done diligently not only to ensure that you are using Azure scale optimally but also to make sure that you are consuming the scale only for the time when you need it, and this can essentially make an enormous impact on your overall operational cost.
We will only be speaking of ADF pipeline and SSIS runtime costs to keep the agenda short and to the point. This article assumes that you have basic understanding of Azure data factory and its integral components, if you are not familiar with it, then it is highly recommended that you should understand the essentials of it by visiting this documentation.
Our scenario was quite simple – we had some pipelines which were scheduled at time and once they are invoked, they further invoke SSIS series of execution of SSIS packages. Once all packages are finished executing, pipelines are said to be finished and that’s the end of the schedule for the day.
First and fore-most consideration which we have considered is, we turned on the SSIS integration runtime infrastructure of ADF right before the time when pipelines were scheduled and added some assumed duration e.g. 4 hours after which IR will be turned off. All of it is simply achieved using Azure automation service and a custom PS based workflows to turn on and off the IR scheduled at time.
So overall initial architecture looked like this



Recently I was working with ADF and was using it for transforming the data from various sources using SSIS and hence ADF’s SSIS integration services became the core necessity to run my data factory pipelines.
When we speak of any cloud-based solution – the design part of it needs to be done diligently not only to ensure that you are using Azure scale optimally but also to make sure that you are consuming the scale only for the time when you need it, and this can essentially make an enormous impact on your overall operational cost.
We will only be speaking of ADF pipeline and SSIS runtime costs to keep the agenda short and to the point. This article assumes that you have basic understanding of Azure data factory and its integral components, if you are not familiar with it, then it is highly recommended that you should understand the essentials of it by visiting this documentation.
Our scenario was quite simple – we had some pipelines which were scheduled at time and once they are invoked, they further invoke SSIS series of execution of SSIS packages. Once all packages are finished executing, pipelines are said to be finished and that’s the end of the schedule for the day.
First and fore-most consideration which we have considered is, we turned on the SSIS integration runtime infrastructure of ADF right before the time when pipelines were scheduled and added some assumed duration e.g. 4 hours after which IR will be turned off. All of it is simply achieved using Azure automation service and a custom PS based workflows to turn on and off the IR scheduled at time.
So overall initial architecture looked like this

Now the interesting bit resides in SSIS packages part – when the series of packages are executed then they are the ones doing the hefty operations on the data and usually interact with some quite large tables. E.g. reading delta from those tables or merging data into them. The process can run from minutes to hours depending upon the data you are dealing with (e.g. reading delta from last week or last day etc.) and during this – we often used to hit the DTU threshold of underlying SQL databases.
Note that hitting DTU threshold does not mean that your pipelines will fail, however the amount of time to finish them completely will increase and what does this mean? This means that for this entire duration of execution, your SSIS runtime needs to be turned ON and this will cost you money.
At the time of writing this, one node of SSIS runtime (1 core, 3.5 GB RAM) provisioned in North Europe data center costs you $ 0.5916 per hour, so even if I am running my pipelines daily which runs for that assumed 4 hours, I would be spending $71.1 per month. Remember, though this still sounds cheap and partial cost effective but there is a good chance to save few more bucks here for sure.
Possible Solutions / Work-around?
- Use of elastic databases?
- Scale out SSIS runtime?
So Ideally, we wanted a solution which can leverage the scale of SQL Azure databases and Integration runtime together but at the same time it should be cost effective.
And hence one possible solution we came up with which is quite straightforward and can easily be divided into below distinct sections
- Turn on the runtime right before pipelines start to run.
- Scale up underlying SQL Azure databases to higher tier e.g. S4
- Wait for scale operation to finish.
- Run the SSIS packages in IR.
- Scale down the SQL database to smallest tier e.g. S0
- Scan pipelines status before scheduler turns off the runtime.
Let’s see how it can easily be visualized
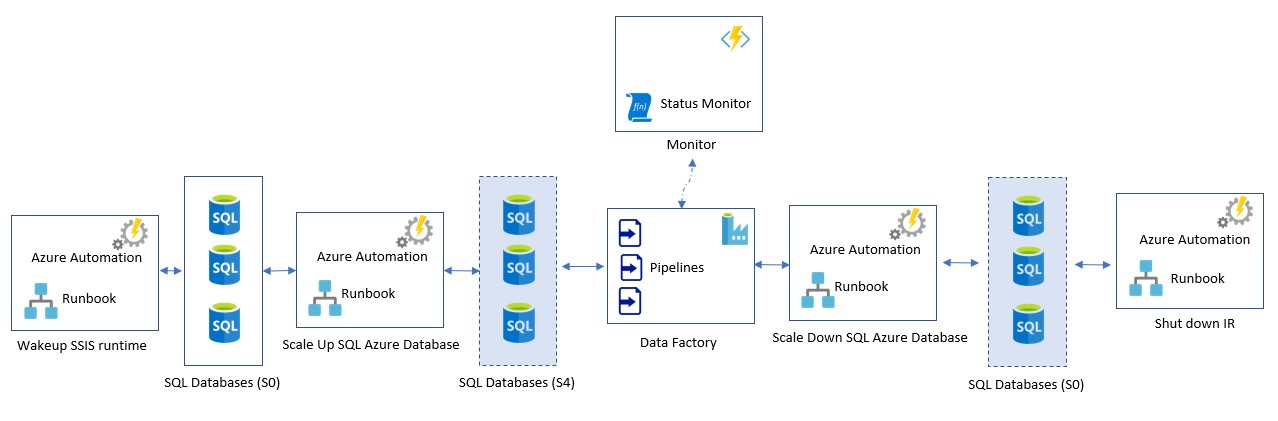
There could be multiple ways to achieve the steps mentioned above, however we chose to implement those using the easiest approach.
Step 1: It was already in place and was achieved using Azure automation so that remained unchanged and untouched.
Step 2 and 5 is again achieved using Azure automation services, we have written a small PS workflow which can vertically scale up or down your databases. All we needed to do was invoke this automation workflow using a webhook which can be called from Azure data factory pipeline. I have already shared the workflow on TechNet gallery so feel free to check it here.
Step 3 is achieved by making use of a small Azure function to whom you can ask the current tier of the input SQL azure database and then use the until (like while in C#) activity in your pipeline to wait till you get the desired tier. Again, the azure functions can be called directly from within your data factory pipeline (Using web activity).
We have used the Until activity in the pipeline to poll the status of database updated tier using the azure function.
Sharing the azure functions bit just for the demonstration purpose. Note that in order to make this function working - you should be creating Azure AD app and give it access to the Windows Azure Service Management Api

Sharing the azure functions bit just for the demonstration purpose. Note that in order to make this function working - you should be creating Azure AD app and give it access to the Windows Azure Service Management Api

Also, ensure that the Azure AD app has got access to the resource group in your subscription containing your SQL azure databases.
We have used the Azure SQL management nuget to talk to management Api, you can refer it https://www.nuget.org/packages/Microsoft.Azure.Management.Sql.
Step 4 – a core activity which can invoke the SSIS package serial execution using a stored procedure. The core command can be checked at here.
We have used the Azure SQL management nuget to talk to management Api, you can refer it https://www.nuget.org/packages/Microsoft.Azure.Management.Sql.
Step 4 – a core activity which can invoke the SSIS package serial execution using a stored procedure. The core command can be checked at here.
Step 6 - Comes the last step i.e. stopping the SSIS runtime node when you have no pipelines running. This again is achieved using Azure automation workflow which triggers itself in every 1 hour (this being minimum trigger frequency available at the time of writing this article) and scans your ADF pipeline’s run status of last 2 hours, if it does not see any running pipeline, it turns of the IR node. i.e. SSIS integration runtime. I have already shared the workflow here, so you can check it out there on TechNet gallery.
You might have already noticed that we have mostly achieved everything either using Azure automation and using azure functions and might have figured the reason behind it too! Yes, the cost – Azure functions does offer you 10 million free executions each month and automation service too offer 500 minutes of process automation free each month.
After implementing this approach, the run time for pipelines has been reduced significantly since SQL Azure database S4 tier offers you dedicated 200 DTUs. With this, one pipeline is getting finished almost within 15 minutes.
And finally, let’s look at the pipeline designer and understand how we have incorporated steps above

Now, let’s do some basic math here and find out appx operational cost difference (skipping data read / write costs)
Previous model:
- SQL database S0 - $0.48 per day
- SSIS runtime up time (4 hours) - $2.347 per day
- Per day operational cost appx $2.82, translates to $84.6 per month.
Updated model:
- SQL database S4 for 1 hour per day – $0.40
- SQL database S0 for rest of the day (23 hours) - $0.46
- SSIS runtime for 1 hour per day - $0.59
- Azure functions – None
- Azure automation – None
- Per day operational cost appx $1.45, translates to $43.5 per month.
Numbers do indicate that the cost seem to have reduced significantly and have reduced it almost to half for each month.
Hope this helps someone who is headed on the same path of running azure infrastructure and solutions in cost effective way.